Business Intelligence & Analytics
Andreas Kensik Unternehmensberatung
KI im Fundraising - Wie Machine Learning zur Response-Optimierung beiträgt
Response-Optimierung am Beispiel von Scoring
Befragen wir erst einmal das künstliche Intelligenzsystem von Microsoft "Copilot". Was versteht der KI-gesteuerte Assistent unter dem Begriff "Machine Learning"?
"Maschinelles Lernen (ML) ist ein Oberbegriff für die „künstliche“ Generierung von Wissen aus Erfahrung. Es ist ein Zweig der künstlichen Intelligenz (KI) und der Informatik, der auf der Grundlage von Daten und Algorithmen den menschlichen Lernprozess imitiert und dabei seine Genauigkeit schrittweise verbessert. Beim maschinellen Lernen bauen Algorithmen ein statistisches Modell auf, das auf Trainingsdaten beruht und welches gegen die Testdaten getestet wird. Das heißt, es werden nicht einfach die Beispiele auswendig gelernt (siehe Überanpassung), sondern Muster und Gesetzmäßigkeiten in den Lerndaten erkannt. "
Genau dieses Verfahren nutzen wir schon seit Jahrzehnten im Scoring zur Berechnung von Response-Wahrscheinlichkeiten. Auch hierzu liefert die KI von Microsoft eine Zusammenfassung, was "Scoring" definiert.
"Scoring ist ein Begriff, der in vielen Bereichen Anwendung findet. Im Zusammenhang mit Machine Learning bezieht sich Scoring auf die Anwendung eines algorithmischen Modells auf einen neuen Datensatz, um praktische Erkenntnisse zu gewinnen, die bei der Lösung eines Geschäftsproblems helfen.
Im Kontext von Machine Learning gibt es verschiedene Methoden, um die Qualität von Vorhersagen zu quantifizieren. Eine Möglichkeit ist die Verwendung von Metriken und Scoring-Methoden, um die Leistung eines Modells zu bewerten. Die Scoring-Methoden können dabei helfen, die Vorhersagegenauigkeit zu verbessern, indem sie die Modellparameter optimieren.
In der Machine-Learning-Praxis gibt es verschiedene Scoring-Methoden, die je nach Anwendungsfall eingesetzt werden können. [...]"
Soweit die Theorie. Aber wie sieht die Anwendung generativer Künstlicher Intelligenz konkret in der Praxis und speziell im Fundraising aus?
Angenommen, ein Fundraiser möchte sein nächstes Spenden-Mailing optimieren. Der Return on Investment der Aktion soll bei gleicher oder reduzierter Auflage gesteigert werden. Ziel ist es nun, aus dem Pool möglicher Adressaten diejenigen zu identifizieren, welche aus mathematisch-statistischer Sicht das höchste Potential haben, auf einen Spendenbrief positiv zu reagieren.
Dazu werden verschiedene Spender-Variablen, die Einfluss auf das zukünftige Spendenverhalten haben könnten, in das Modell integriert. Neben den üblichen RFM- Variablen (Recency, Frequency Monetary Value) aus der Spendenhistorie kann das selbstlernende statistische Modell auch mit soziodemografischen Informationen oder Spendertypisierungen angereichert, insofern vorhanden.
Die statistischen Wahrscheinlichkeiten werden anhand eines Response-Score-Wertes abgebildet und jeder Spender-ID zugeordnet. Es gibt Score-Kategorien von Null bis Eins. Je näher der Wert an Eins liegt, desto höher ist die Wahrscheinlichkeit einer positiven Reaktion.
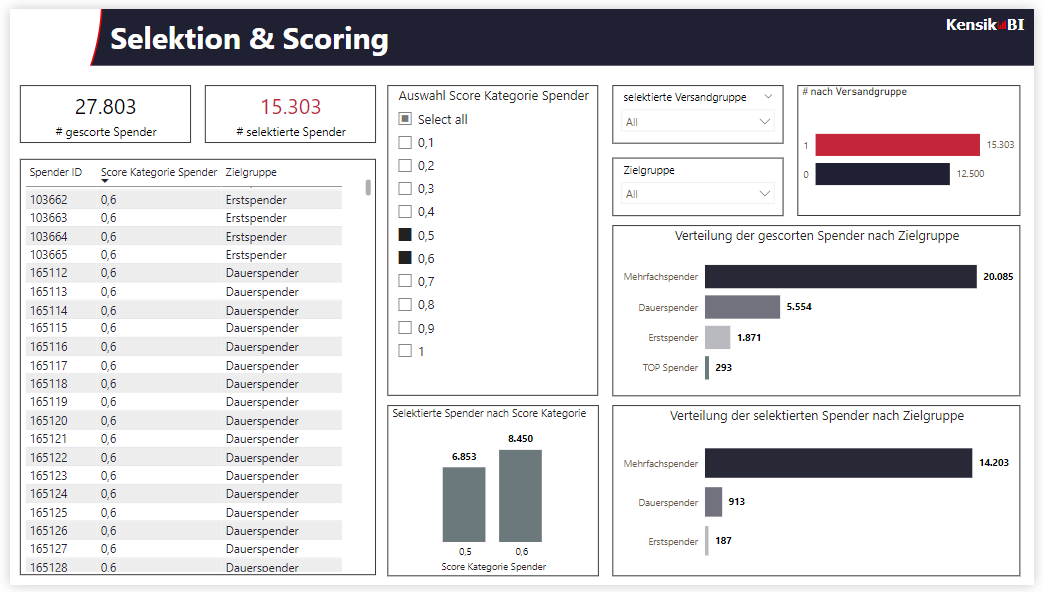
Beispielsweise können über einen organisationsspezifischen und interaktiven Bericht (hier Power BI) relevante Filtereinstellungen zur Selektion gescorter Mailing-Adressaten vom Fundraiser selbst variiert werden. Die Auswahl gewünschter Response-Score-Wahrscheinlichkeiten (Score-Kategorien) führt zu einer entsprechenden Selektion der gescorten Spender in der Spenderdatenbank. Entsprechend ändert sich, je nach ausgewählten Score-Werten sowie ggfls. weiteren Filtereinstellungen, die maximal mögliche Auflagengröße in dieser Kombination.
In diesem Beispiel eines mit der Spenderdatenbank verknüpften Power BI Berichts, kann auf Basis der interaktiven Vorgaben und Einstellungen des Fundraisers intern eine Liste mit den Spender IDs selektiert und für die Mailingproduktion exportiert werden.
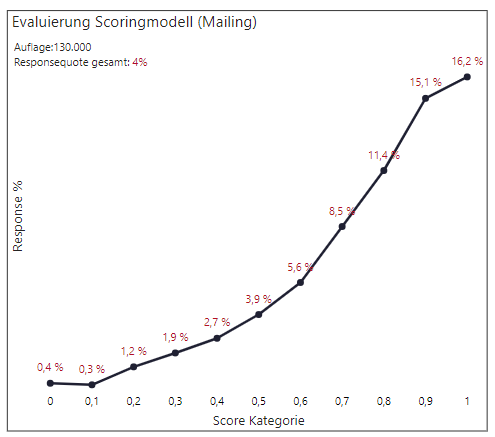
Bei selbst lernenden Modellen im Scoring ist es sinnvoll, ein paar Monate nach der Aussendung bzw. Beendigung einer Kampagne, eine Evaluierung durchzuführen. Anhand der Responsedaten wird die Qualität des Vorhersage-Modells bewertet und für das nächste Scoring mit den erweiterten Daten "gefüttert". Idealerweise sollte es auch eine Kontrollgruppe aus den gescorten Adressaten geben, um die Validität der Ergebnisse zu sichern. Die Kurve der Beispielgrafik zeigt, das hier zugrunde liegende Modell hat eine gute Vorhersage geliefert. Mit ansteigender berechneter Wahrscheinlichkeit (Score Kategorie) erhöhte sich auch die tatsächliche Responsequote des Mailings.
Befragen wir zum Abschluss noch einmal die Künstliche Intelligenz: Was sind denn typische Responsequoten von Mailings?
"Die Response-Quote kann stark variieren, je nach Ausgestaltung des Mailings, der angeschriebenen Zielgruppe und den Adressen, die verwendet wurden. Bei Empfängern, mit denen Sie noch nicht in Kontakt standen, liegen die Response-Raten bei 0,5 bis 2 Prozent. Etwa 1 Prozent Response ist die Regel. Aussendungen an eigene Kunden mit einem neuen Angebot haben meist eine Response-Rate zwischen 2 bis 10 Prozent. Aussendungen an eigene Kunden mit einer Einladung zu einem Event können teilweise sogar über 10 Prozent Response erreichen."
